What `fn(args, deps)` actually gives you in DDD-style TypeScript
18 Mar 2026Domain-Driven Design comes with a lot of vocabulary: aggregates, repositories, domain services, bounded contexts, ubiquitous language, anemic models.
That vocabulary can make DDD sound heavier than it really is.
The useful idea is simpler: keep domain behavior and domain boundaries central, and keep infrastructure, persistence, and framework wiring secondary.
fn(args, deps) does not do that modeling for you. What it gives you is a clear shape for application-layer code in TypeScript: one place for use-case input, one place for collaborators, and less room for domain decisions to drift into wiring.
DDD as pressure, not prescription
A lot of DDD discussions get pulled into implementation details too early.
People hear "DDD" and picture layered systems, elaborate abstractions, or class-heavy code full of patterns used more out of loyalty than necessity.
That is not the useful part.
The useful pressure from DDD is much more direct:
- focus on the language of the domain
- protect important invariants
- define boundaries around aggregates
- keep infrastructure secondary to business behavior
That pressure matters whether your code uses classes, plain objects, pure functions, or a mix.
This is where fn(args, deps) becomes useful.
Not as a substitute for DDD, but as a repeatable way to structure application code around the model instead of around the framework.
That is a narrower claim than "this is DDD," but it is also the more useful one.
Aggregates and invariants in TypeScript
In plain terms, an aggregate is a consistency boundary.
It is a boundary around related domain state that must remain valid through rules enforced by a single root. The aggregate root is the entry point through which those invariants are protected.
That sounds abstract, so here is a small example.
Imagine an order that can contain line items, can be cancelled, and can be shipped. One invariant might be that a cancelled order cannot be shipped.
Another might be that you cannot add lines once the order has shipped.
In TypeScript, that does not require a giant inheritance hierarchy. The domain model can stay small and direct.
type OrderId = string;
type OrderStatus = "draft" | "placed" | "cancelled" | "shipped";
type OrderLine = {
productId: string;
quantity: number;
};
type Order = {
id: OrderId;
status: OrderStatus;
lines: OrderLine[];
};
const addLine = (order: Order, line: OrderLine): Order => {
if (order.status === "shipped") {
throw new Error("Cannot add lines to a shipped order");
}
if (order.status === "cancelled") {
throw new Error("Cannot add lines to a cancelled order");
}
if (line.quantity <= 0) {
throw new Error("Quantity must be greater than zero");
}
return {
...order,
lines: [...order.lines, line],
};
};
const ship = (order: Order): Order => {
if (order.status === "cancelled") {
throw new Error("Cannot ship a cancelled order");
}
if (order.lines.length === 0) {
throw new Error("Cannot ship an order with no lines");
}
return {
...order,
status: "shipped",
};
};In production code, I would usually prefer explicit domain error types over generic Error values, but Error keeps the examples smaller here.
This is already recognizable as domain logic.
The important point is not whether this is written as a class or as pure functions over a value.
The important point is that the rules live with the domain behavior, not buried in controllers, handlers, or database code.
That part is standard DDD. The more interesting question is what happens once an application use case has to load that model, persist it, and coordinate what comes next.
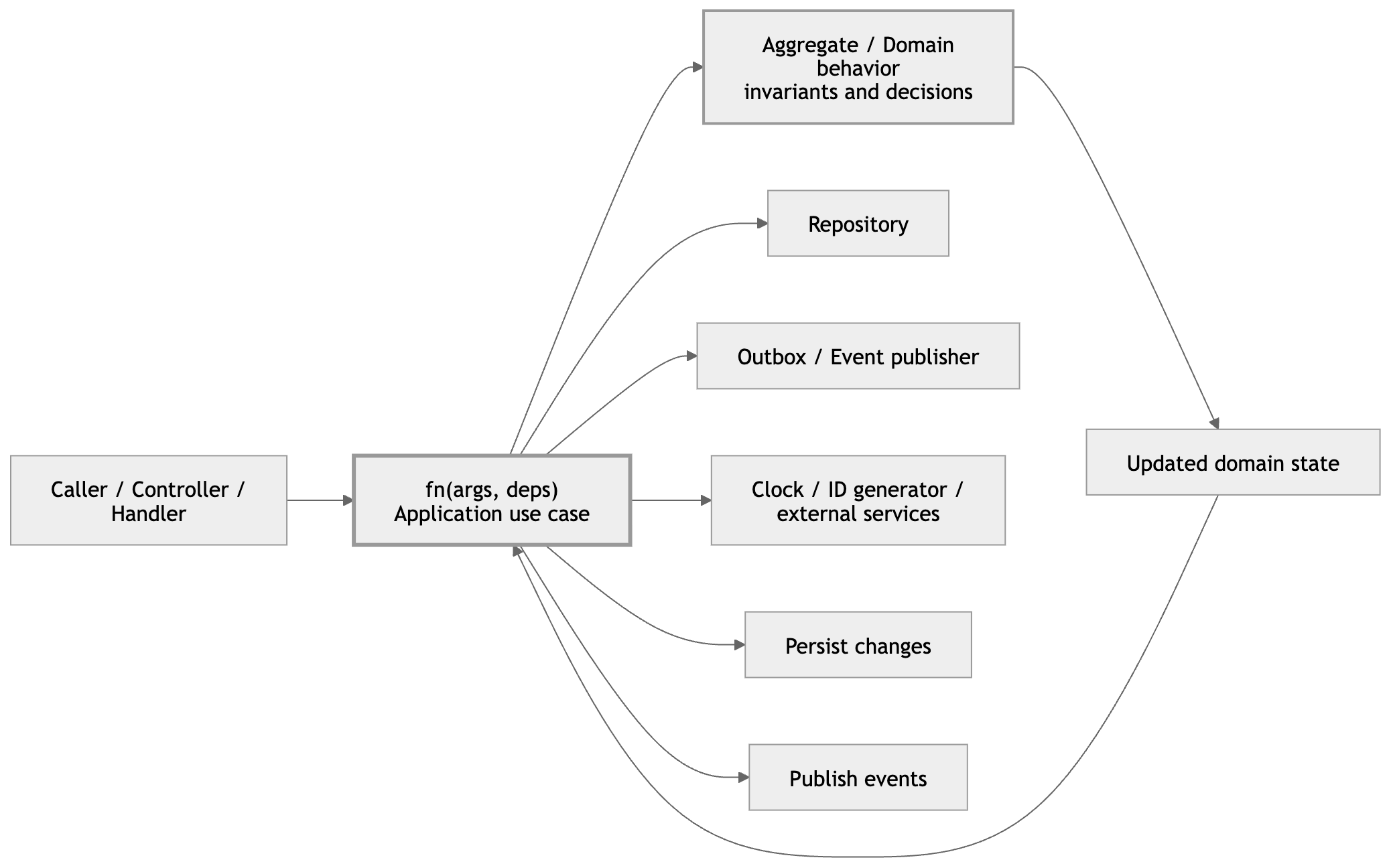
Where fn(args, deps) actually helps
In a DDD-influenced system, fn(args, deps) fits most naturally in the application layer.
That means it acts like a use case or application service. It loads an aggregate, invokes domain behavior, persists the result, and coordinates side effects.
If you like the “inside vs outside” framing, this is the same boundary idea as hexagonal architecture. The wiring still happens at the edge in a composition root.
That last part matters.
The function shape is helpful only if the application layer stays a coordinator. The model should still carry the meaning of the business rules.
A simple shipOrder(args, deps) might look like this:
type ShipOrderArgs = {
orderId: string;
};
type ShipOrderDeps = {
orders: {
getById(id: string): Promise<Order | null>;
save(order: Order): Promise<void>;
};
domainEvents: {
publish(events: { type: string; orderId: string }[]): Promise<void>;
};
};
export const shipOrder = async (
args: ShipOrderArgs,
deps: ShipOrderDeps,
): Promise<void> => {
const order = await deps.orders.getById(args.orderId);
if (!order) {
throw new Error("Order not found");
}
const shippedOrder = ship(order);
await deps.orders.save(shippedOrder);
await deps.domainEvents.publish([
{
type: "OrderShipped",
orderId: shippedOrder.id,
},
]);
};There is a clean split here:
argsis command-shaped inputdepscontains infrastructure-facing collaborators- the domain rule stays in domain behavior
- the function itself orchestrates the use case
For teams that want clear boundaries without a heavy framework or a class hierarchy, that is already a meaningful improvement.
Avoiding anemic domain models without overcorrecting
One of the standard critiques in DDD discussions is the anemic domain model: objects that carry data while the important decisions live elsewhere.
That critique is still useful.
But there is also a common overcorrection where people assume every bit of behavior must live on a large entity class or the design has somehow failed.
fn(args, deps) helps with the first problem without forcing the second.
Here is the weak version:
type CancelOrderArgs = {
orderId: string;
};
type CancelOrderDeps = {
orders: {
getById(id: string): Promise<Order | null>;
save(order: Order): Promise<void>;
};
};
export const cancelOrder = async (
args: CancelOrderArgs,
deps: CancelOrderDeps,
): Promise<void> => {
const order = await deps.orders.getById(args.orderId);
if (!order) {
throw new Error("Order not found");
}
if (order.status === "shipped") {
throw new Error("Cannot cancel a shipped order");
}
if (order.lines.length === 0) {
throw new Error("Cannot cancel an empty order");
}
await deps.orders.save({
...order,
status: "cancelled",
});
};This works, but the use case is making domain decisions directly.
The order is mostly a data bag.
When that happens repeatedly, the code may use DDD vocabulary without really letting the domain model do domain work.
A better version moves the decision back into domain behavior:
const cancel = (order: Order): Order => {
if (order.status === "shipped") {
throw new Error("Cannot cancel a shipped order");
}
if (order.lines.length === 0) {
throw new Error("Cannot cancel an empty order");
}
return {
...order,
status: "cancelled",
};
};
export const cancelOrder = async (
args: CancelOrderArgs,
deps: CancelOrderDeps,
): Promise<void> => {
const order = await deps.orders.getById(args.orderId);
if (!order) {
throw new Error("Order not found");
}
await deps.orders.save(cancel(order));
};That is the distinction that matters.
The point of the pattern is not to drag decisions upward into orchestration. It is to keep orchestration honest while leaving the rules with the model.
Aggregate boundaries become easier to see
One practical side effect of fn(args, deps) is that aggregate boundaries become easier to see.
In DDD-style systems, repositories are often modeled around aggregate roots. That means the dependency list for a use case often acts as feedback on the shape of the model.
For example:
type ApproveInvoiceDeps = {
invoices: InvoiceRepository;
customers: CustomerRepository;
creditPolicies: CreditPolicyService;
outbox: OutboxWriter;
};Sometimes that is perfectly reasonable.
Sometimes it is a warning sign.
If a single use case keeps needing multiple repositories, cross-aggregate reads, extra coordination services, and transaction workarounds, the code is often telling you something about the boundary you picked.
That is one of the more practical benefits of the pattern.
Because dependencies are explicit, awkward boundaries become harder to ignore. Instead of disappearing into injected class state or framework wiring, the complexity stays visible in the use case signature.
That is useful in code review, in refactoring, and in the earlier stages of figuring out where aggregate boundaries really belong.
Transactions are where reality starts
This is also where the pattern stops being self-explanatory.
The earlier shipOrder(args, deps) example is fine as a teaching example, but real systems have to care about failure between steps. If orders.save succeeds and outbox.append fails, you have now persisted new state without recording the event the rest of the system may depend on.
fn(args, deps) does not solve that problem by itself.
What it does do is give you an obvious place to model the transactional boundary explicitly:
type ShipOrderDeps = {
withTransaction<T>(
work: (tx: {
orders: {
getById(id: string): Promise<Order | null>;
save(order: Order): Promise<void>;
};
outbox: {
append(events: { type: string; orderId: string }[]): Promise<void>;
};
}) => Promise<T>,
): Promise<T>;
};
export const shipOrder = async (
args: ShipOrderArgs,
deps: ShipOrderDeps,
): Promise<void> => {
await deps.withTransaction(async (tx) => {
const order = await tx.orders.getById(args.orderId);
if (!order) {
throw new Error("Order not found");
}
const shippedOrder = ship(order);
await tx.orders.save(shippedOrder);
await tx.outbox.append([
{ type: "OrderShipped", orderId: shippedOrder.id },
]);
});
};You can model that as a unit of work, a transaction wrapper, an outbox writer inside a transaction, or something equivalent.
The abstraction can vary. What matters is that transaction coordination is an explicit application-layer decision, not an invisible assumption.
Domain events are a design choice, not a freebie
Domain events are another place where fn(args, deps) fits naturally.
Some teams model domain events as part of the domain result. Others derive them in the application layer after a domain operation. Either way, fn(args, deps) gives you a clear place to persist state and then hand those events to an explicit dependency such as an event publisher or outbox writer.
type SaveResult = {
order: Order;
events: { type: string; orderId: string }[];
};
const shipWithEvents = (order: Order): SaveResult => {
const shippedOrder = ship(order);
return {
order: shippedOrder,
events: [{ type: "OrderShipped", orderId: shippedOrder.id }],
};
};
type ShipOrderWithOutboxDeps = {
orders: {
getById(id: string): Promise<Order | null>;
save(order: Order): Promise<void>;
};
outbox: {
append(events: { type: string; orderId: string }[]): Promise<void>;
};
};
export const shipOrderWithOutbox = async (
args: ShipOrderArgs,
deps: ShipOrderWithOutboxDeps,
): Promise<void> => {
const order = await deps.orders.getById(args.orderId);
if (!order) {
throw new Error("Order not found");
}
const result = shipWithEvents(order);
await deps.orders.save(result.order);
await deps.outbox.append(result.events);
};In this version, the domain operation returns events rather than storing them on the aggregate itself.
That is a design choice, not a law of DDD.
Some teams prefer aggregates to collect events internally and expose them after the operation. In function-oriented code, returning the events directly often keeps side effects more visible and avoids hidden mutable state. But that is a stylistic preference, not something the domain model forced on you.
The main win is simpler than that: the eventing concern stays explicit without smuggling infrastructure mechanics into every domain type.
Keep TypeScript dependency typing practical
One fair criticism of this style is that dependency typing can get repetitive in large codebases.
If every use case hand-writes an inline repository shape with getById and save, the code stays explicit but starts to feel noisy.
That is usually a sign to standardize the building blocks without giving up the narrow dependency surface:
type Repository<T> = {
getById(id: string): Promise<T | null>;
save(entity: T): Promise<void>;
};
type ShipOrderDeps = {
orders: Pick<Repository<Order>, "getById" | "save">;
outbox: OutboxWriter;
};That keeps the use case honest about what it needs while avoiding copy-pasting the same method signatures across dozens of files.
The useful constraint is not "write every dependency type from scratch forever."
The useful constraint is "make dependencies explicit and keep them narrower than the whole container."
Why teams tend to like this shape
The appeal is not theoretical purity. It is consistency.
useCase(args, deps) gives teams a predictable entry point, makes collaborators easy to inspect, keeps testing straightforward, and exposes anemic designs by making repeated decisions easier to notice.
In practice, that means less hunting through framework wiring to figure out where a business action starts and what it actually depends on.
Where this pattern stops
It is worth being precise here.
fn(args, deps) does not solve strategic DDD. It does not define bounded contexts, create a ubiquitous language, discover aggregate boundaries, or model long-running workflows for you.
And tidy function signatures definitely do not guarantee a good domain model.
Those things still require domain knowledge, modeling effort, and iteration.
Once a business process crosses multiple aggregates, multiple transactions, or multiple services, a tidy useCase(args, deps) per step is no longer the whole story. You now need workflow coordination, retry behavior, idempotency, and eventual consistency concerns that live above a single aggregate use case.
That is not a failure of the pattern. It is just the boundary of what the pattern is for.
What this pattern does give you is a low-ceremony way to express application-layer decisions clearly once you have started making them.
Why this still matters
DDD is about domain focus, domain language, and domain boundaries.
fn(args, deps) does not do that work for you. What it does do is give the work a clear place to live: domain rules in domain behavior, coordination in the application layer, and infrastructure at the edges.
None of this removes the need to model responsibilities well inside the domain; it only gives those responsibilities a cleaner application boundary.
That is a modest promise, but in real TypeScript systems it is often the difference between code that merely mentions DDD and code that can actually support it.