Secure AI Apps Start With Functions, Not SQL
13 May 2026If you're building AI features into your product, the temptation is to hand the model a database connection and let it write SQL.
It feels powerful. It feels like the modern way.
It's the wrong place to start.
The same reasoning applies whether you're building a CLI, a Slack bot, an MCP server, or an agent.
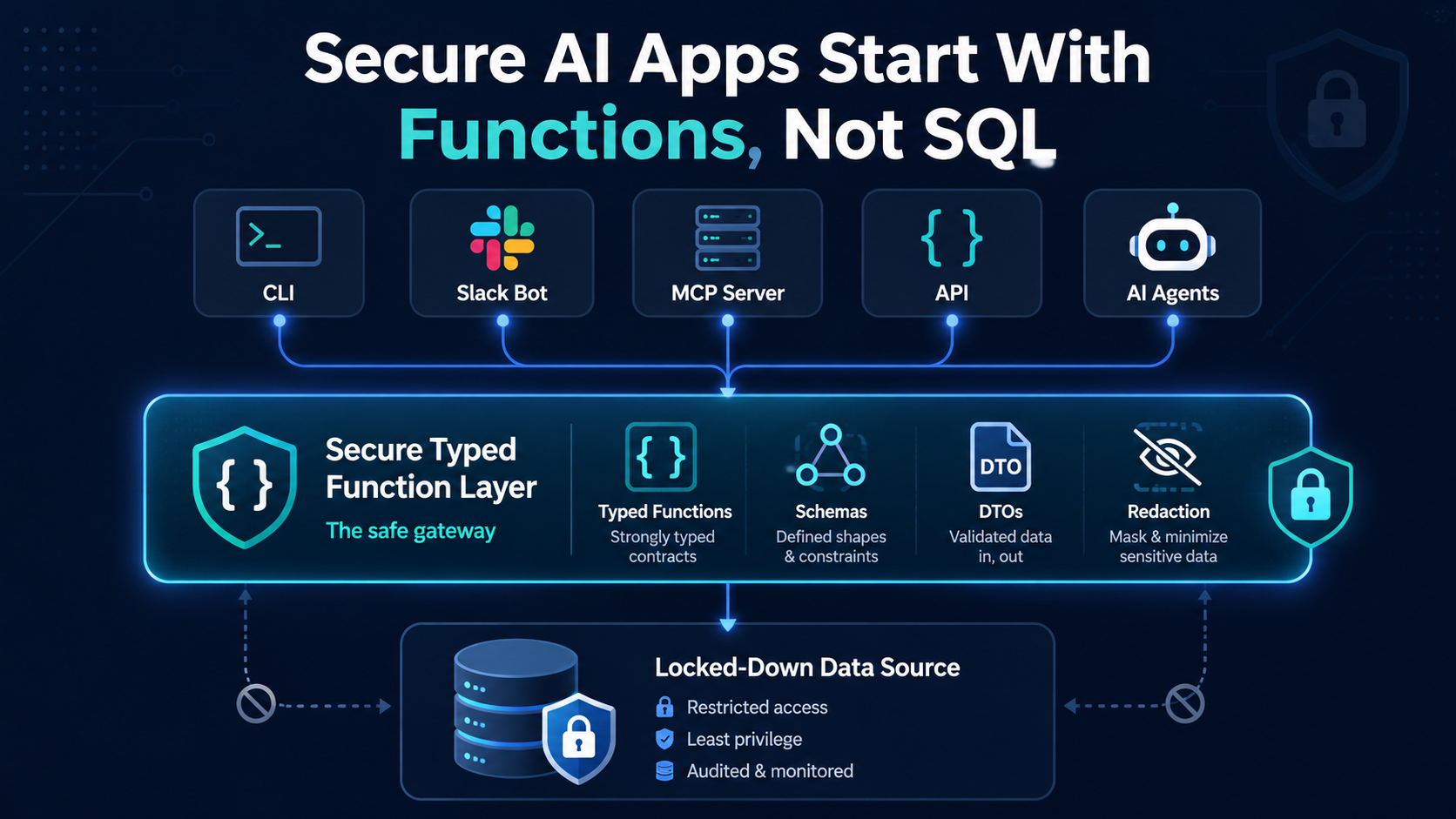
tl;dr: Build a typed, composable function layer first. Lock down the database, shape responses with DTOs, redact sensitive fields, and expose only those safe functions to CLIs, Slack bots, MCP servers, and agents. The AI layer is easy to swap. The function layer is what matters.
Functions, not prompts
In most product use cases, you don't need text-to-SQL at all. You need a small set of predefined functions that do useful things.
If you're building around payments, that might look like:
getLatestPaymentsForClient(clientId)
getFailedPaymentsForClient(clientId)
getClientPaymentSummary(clientId)Each function does one thing, takes a fixed set of arguments, and returns predictable JSON. Good JSDoc, typed inputs, typed outputs, a clear purpose. That is the foundation.
Not prompts. Not agents. Not text-to-SQL. Functions.
The reason this matters is composability. If a function has a single responsibility and returns structured JSON, anything can sit on top of it: a CLI, a Slack bot, an MCP server, an HTTP API, an agent. The contract is fixed, so you always know what goes in and what comes out.
flowchart TD
DB[("Approved data source")]
Core["Core functions<br/>typed inputs, safe outputs"]
CLI["CLI"]
Slack["Slack bot"]
MCP["MCP server"]
API["HTTP API"]
Agents["AI agents"]
DB --> Core
Core --> CLI
Core --> Slack
Core --> MCP
Core --> API
Core --> Agents
Read that diagram as: one safe layer in the middle, many ways for people and machines to use it.
Build the CLI or Slack bot first
Before you add any AI at all, I'd actually recommend wiring up a CLI or a Slack bot.
It sounds backwards, but it forces you to design the interaction model properly. Start with a simple menu of domains:
Clients
Payments
Invoices
Orders
Within each domain the user picks an action: latest payments for a client, failed payments, account summary, recent invoices. They're calling the same predefined functions an agent would call, just through a menu instead of natural language.
This is a good thing, because the first job is not making it intelligent. The first job is making it safe.
Least privilege starts at the database
Do not expose more than you need to.
Start with a read-only database connection. Better still, create a database user that only has access to the specific tables or collections the tooling needs.
If your database contains API keys, secrets, admin data, audit logs, or sensitive customer records, your AI tooling should not be able to touch those tables at all. That's the first security boundary.
The second boundary is the function itself. Even when the database user can read a table, the function should not return everything from it. This is where DTOs earn their keep.
A payment record might have twenty internal fields. The function returns six:
{
"paymentId": "pay_123",
"clientName": "Acme Ltd",
"amount": 1200,
"currency": "GBP",
"status": "paid",
"createdAt": "2026-05-01"
}No raw metadata, no internal IDs, no private fields, no PII unless it's genuinely required.
That JSON is what the engineer sees. The business user sees something like this in Slack:
Acme Ltd Last payment: £1,200 on 1 May 2026 Status: Paid Outstanding invoices: 2 (£3,400) Open support tickets: 1
Same data, same function call, just rendered for a human instead of piped to another tool. A salesperson can pull that up before a call, a support agent can quote it on a ticket, and an AI agent can read it as context. None of them need direct database access to do it.
Database permissions can restrict tables and sometimes columns, but they can't shape responses per use case. DTOs can, and they give you a natural place to redact. If a value should never reach Slack, the CLI, the MCP server, or the model, redact it before it leaves the function. Your AI layer should never be the thing deciding what's safe.
What you've actually built
By this point you have something stronger than "an AI app":
- a read-only database user with restricted table access
- a set of approved functions
- DTOs that only expose safe fields
- redaction at the function boundary
- JSON schemas for predictable outputs
- typed inputs and outputs end to end
And because the output is structured JSON, the CLI gets a useful side effect for free. You can pipe through jq:
payments list --client acme --json | jq '.[] | select(.status == "failed")'That's the same composability the AI layer will need, just exposed to humans first. If jq can chain your tools cleanly, an agent can too.
Now you're ready for AI
The key is not "give the model SQL access". The key is deciding which use cases AI should actually support.
Maybe you need a payments agent, a client insights agent, a support agent, a sales enablement agent. Each one only gets the tools it needs. The payments agent gets payment tools. The support agent gets support tools. No agent gets broad access. No agent invents arbitrary queries.
You can put a routing agent at the front to send a request to the right specialist, and each specialist can have its own instructions and few-shot examples. But the agents are not the foundation. The tools are. The functions are. The schemas are. The safe data shapes are.
With TypeScript, Pydantic, Zod, or JSON Schema, the entire chain is type-safe end to end. You know what each tool takes, what it returns, how to validate it, and how to document it. That matters a lot once a function becomes an AI tool, because the description, the name, the schema, and the return shape all become part of the prompt the model reads.
This is why the core function layer deserves the most effort.
A note on the database itself
Your AI features and internal tools should ideally not hit production directly.
A read replica is a good first step: a bad query won't take down the live application. A better setup is change data capture, like CDC or MongoDB change streams. You capture events from production and write them into a separate database that exists specifically for internal tooling, reporting, and AI.
That database is read-only from the AI app's perspective. It only contains the fields these tools are allowed to consume. It can store redacted or transformed versions of records. If something ever goes wrong, you revoke one connection string without touching production.
flowchart LR
Prod[("Production database")]
Stream["Change events"]
Tool[("Tooling database<br/>read-only, redacted")]
Core["Core functions"]
Users["CLI / Slack / MCP / Agents"]
Prod -->|CDC or events| Stream
Stream --> Tool
Tool --> Core
Core --> Users
The arrows only go one way. Nothing on the right can write back to production.
If you already have event-driven architecture, this is even cleaner. The tooling database is just another subscriber. You can choose between thin events (minimal payload, requires another lookup) and fat events (the full approved payload). For AI and internal tooling, fat events are often more useful, because the event itself can carry exactly what the tools are allowed to see.
If CDC or events aren't on the table yet, dual-writing from the application to a tooling database is a fallback. It's not perfect, but it's still better than handing AI broad access to production.
Don't forget observability
Whatever shape this takes, you need to know what's happening: which tools are being called, by whom, with what arguments, what they returned, which agents called which functions, where errors are happening, and whether anyone is trying to use the tools in ways the design didn't anticipate.
Security isn't only about blocking access. It's also about being able to see what's going on.
What this unlocks
With this foundation, the same function layer powers a lot of useful things at once. Customer support can answer questions faster. Account managers can pull client activity without filing tickets. Sales can get context before a call. Operations can investigate issues without engineering help.
In the repo, the effort goes into one place: a core package holding the functions, DTOs, schemas, types, redaction, descriptions, OpenAPI specs, and MCP tool definitions. Everything else just consumes core:
/packages
/core
/cli
/slackbot
/mcp-server
/api
/agents
Every surface shares the same logic, the same DTOs, the same safety rules.
The mistake is thinking the AI layer is the product. It usually isn't.
The real product is the secure, typed, composable function layer underneath.
AI is just another interface on top of it, and probably not the last one you'll add.