Support asks a year after the payment: "Why did the customer receive €117? And which card did we charge?"
A supportable system answers that with one query. If answering means trawling archived logs, guessing what the exchange rate was that day, and hoping nobody edited the payment method since, you don't have a supportable system.
Record the decision at the point you make it, and never destroy the data it points to.
A confident voice can ask a sharp question at the wrong moment and close a room down. In a meetup, the cost is one nervous speaker and a room that goes quiet. In a company, the same habit compounds, meeting after meeting, until the same few people decide what the team is allowed to say out loud.
You see the pattern at conferences first. The people who are confident keep speaking. The people finding their voice hold back. Over time the room narrows. The same voices return, the same ideas circulate, and the different takes never get a hearing.
Most Claude Code sandbox guides sell convenience. Fewer prompts, smoother flow, less time approving commands.
But what about the blast radius?
When an AI agent runs a command, it does not only run the command you had in mind. It runs every child process, package script, setup hook and recovery step that command sets off.
A helpful agent reads a README, installs a dependency, retries a failed setup step, and turns "get this project running" into "execute whatever this project tells me to execute."
The sandbox is a boundary, not a trust button. And the boundary only protects you to the extent you configure it.
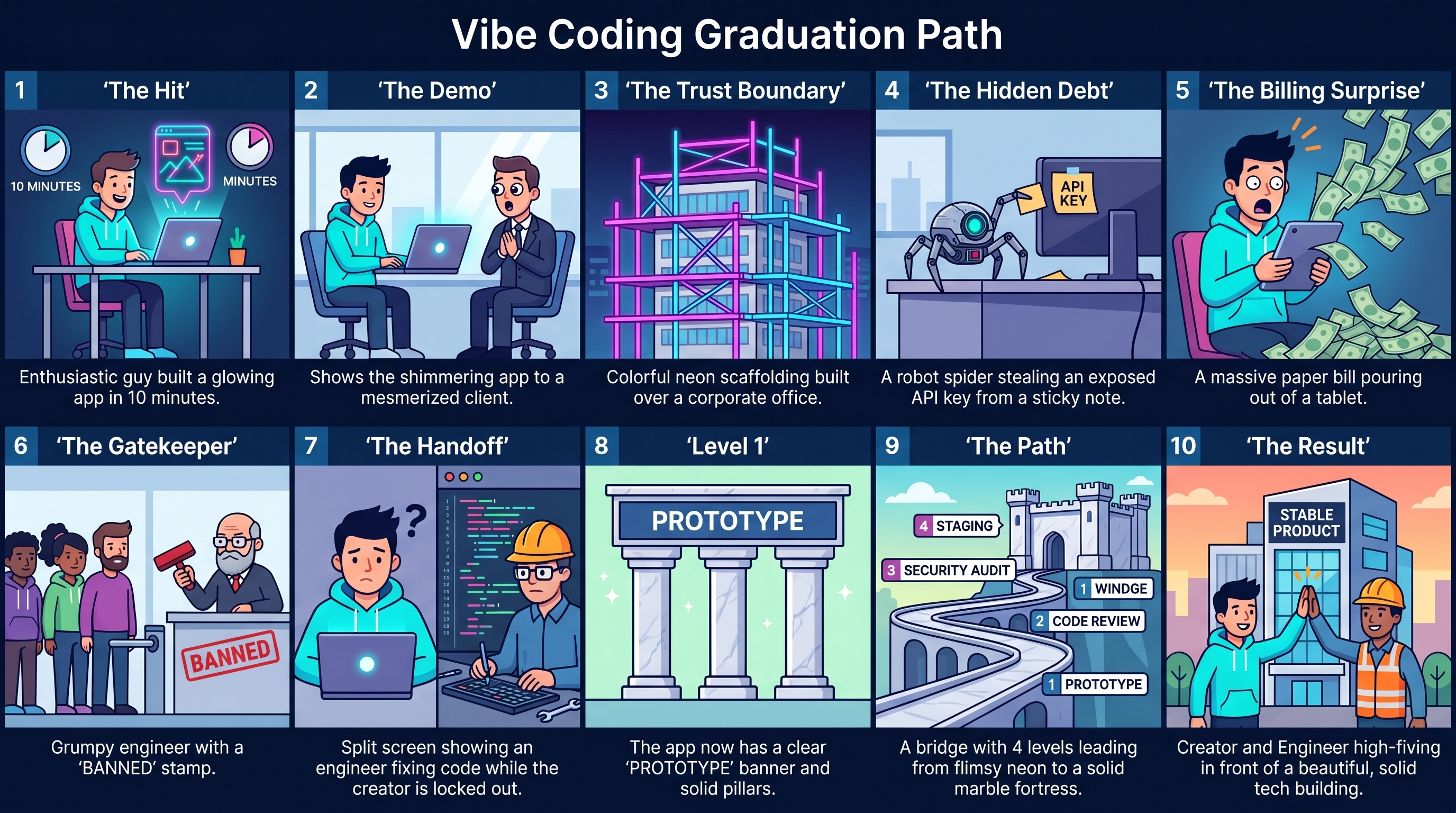
I’ve seen non-developers build apps that would have taken engineers days, if not weeks.
Not just functional apps, but polished apps with rich functionality that bring joy to users. They meet real needs, and the attention to detail is unmatched.
Product people and domain experts can build good apps, and they build them fast.
So the question is: when does a vibe-coded app become a real product?
That is the question a lot of companies are about to face.
In many businesses, engineers are no longer the only people building the next prototype. Client managers, sales teams, product people and domain experts build it too, using tools like Lovable, Base44, Claude and other AI app builders.
@jagreehal/sandbox-node runs your npm install in a throwaway container that can see your project and the registry, and nothing else.
Install scripts still run. node-gyp still builds. Your SSH keys, npm token, cloud credentials, and .env are not in the box, so a malicious dependency has nothing to steal and nowhere to send it.
The most-recommended npm defence right now is a cooldown: refuse to install any version published more recently than a few days ago. pnpm shipped it as minimumReleaseAge, Aikido Safe Chain turns it on by default, and after the recent Shai-Hulud-style npm worms, it became the advice everyone repeats.
It is good advice. It closes the window these worms detonate in. But "set a cooldown" is being sold as if it were the whole answer, and it is not. A cooldown knows one thing about a package: how old it is. There are at least three reasons it is not enough on its own, and for those, age is the wrong question to ask.
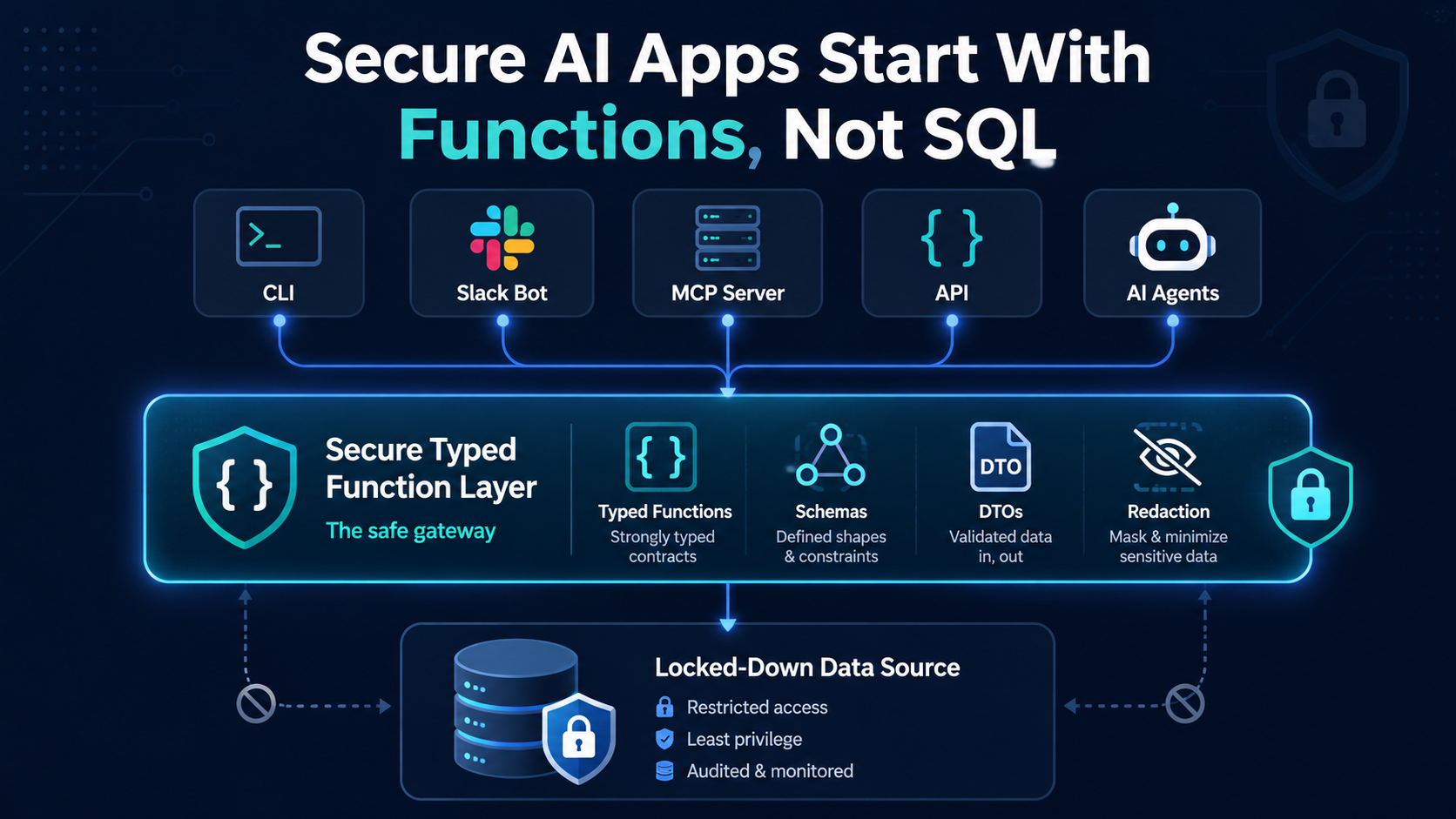
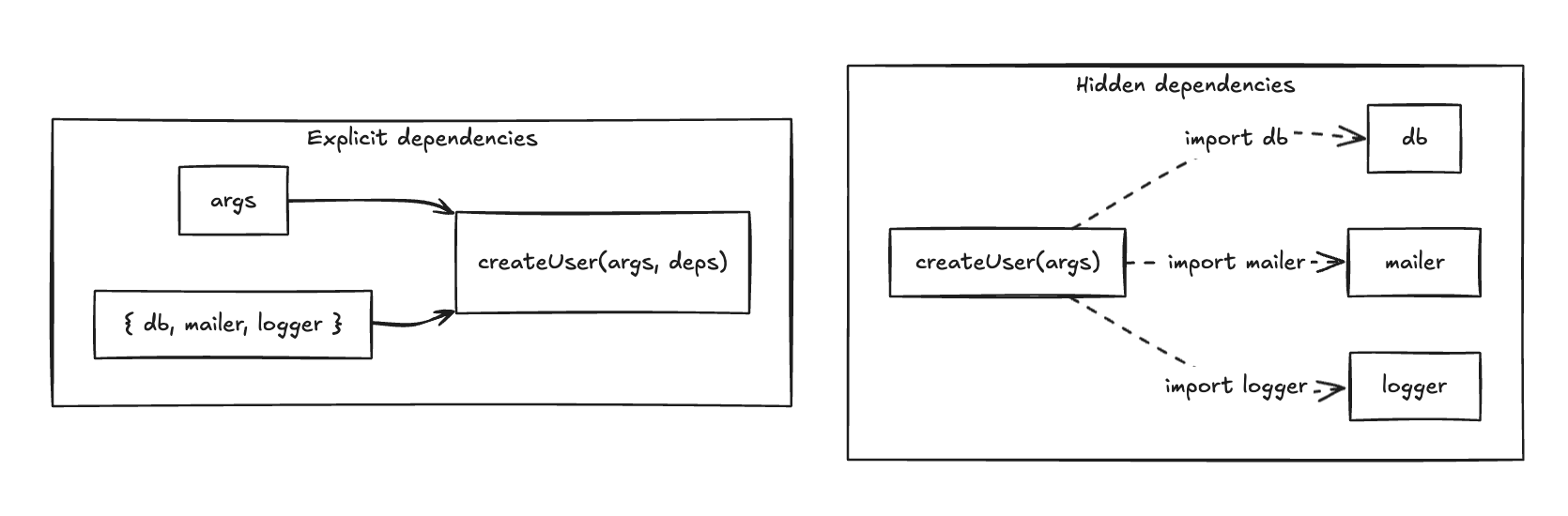
You run npm install without thinking. It looks like a download step. It is a trust decision.
Every package that resolves into your tree can run code the moment it installs, with the same access you have: your SSH keys, the npm token in ~/.npmrc, your cloud credentials, your .env. Not the package you typed. Any of the hundreds underneath it. You approved none of them by name, and the package manager never asked.
The fix is not to read more or trust less. It is to run that install somewhere your secrets are not.
In the middle of a supply-chain incident, the maintainer is not just fixing packages. They are locked out of their account, answering reports, trying to contact registries, trying to warn users, and trying to prove what happened.
That is the part we do not talk about enough.
Most open source maintainers are not companies. They do not have incident response teams. They do not have a security department. They have a GitHub account, an npm account, a laptop, and a lot of people depending on them.
Security advice often assumes the maintainer is the weak link. That is backwards. The maintainer is the last line of defence, usually unpaid, usually alone, and often locked out of the systems they need during the incident.
This is the checklist I wish every maintainer had before something goes wrong. No single setting saves you, so it works in layers: the account, the branch, the release path, the workflow, the tokens, the files, the tripwires, and the recovery plan.
In June 2026, a self-propagating npm worm compromised maintainer accounts and republished their packages with malware inside. Maintainers woke to hundreds of malicious versions across dozens of packages, often published in a few minutes overnight.
Many of those versions went out through npm's trusted publishing, the tokenless way to publish from CI, and they carried valid provenance. The green badge, the Sigstore attestation, the "built from this repo by this workflow" proof: all real.
The worm never needed an npm password for those publishes. It used the release pipeline itself.
Trusted publishing remains the right approach. Many configurations leave one field blank, and that blank field is the gap. Closing it takes about five minutes per package. This post shows the attack and the settings that would have stopped the snapshot-branch half of it.
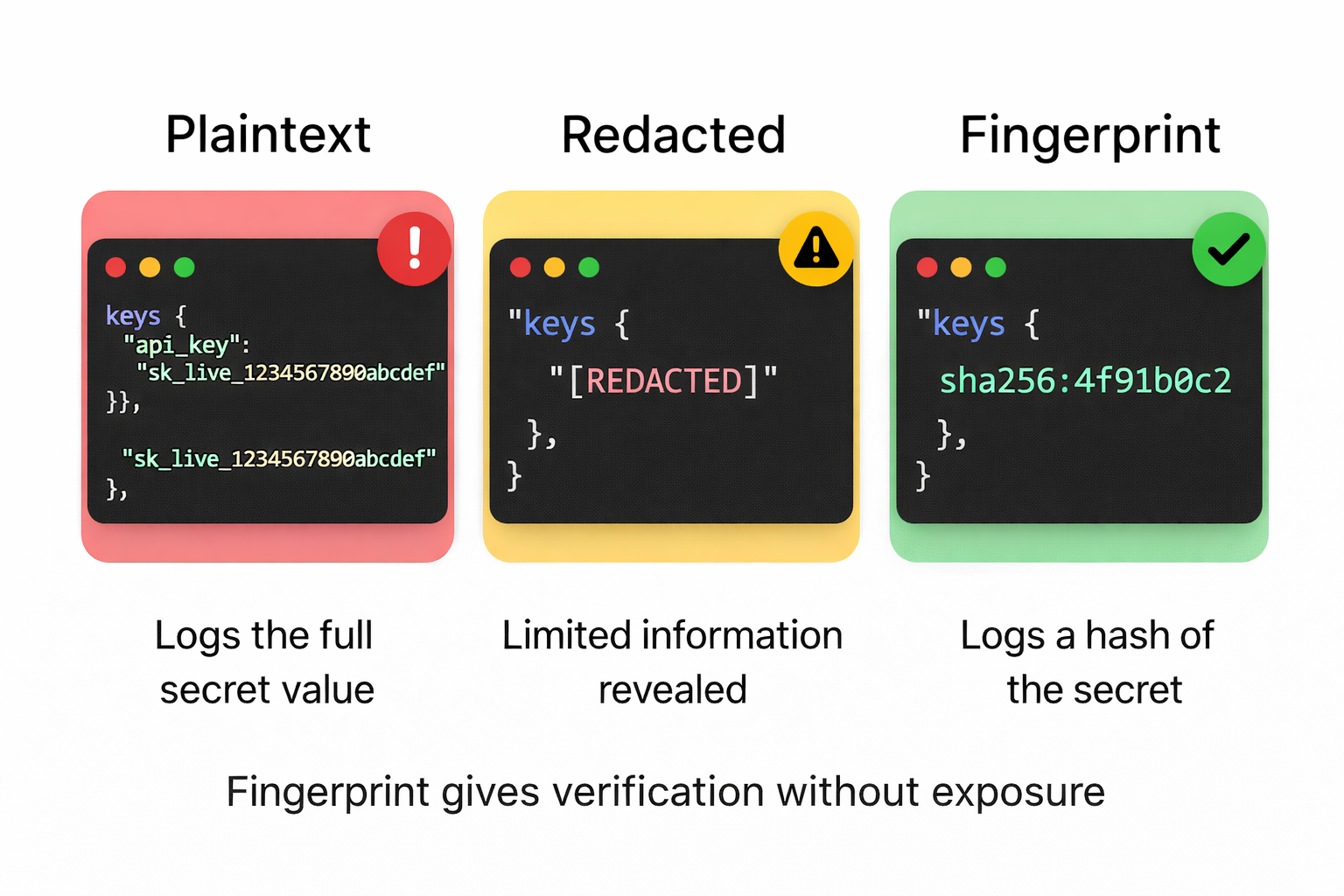
You may inadvertently expose sensitive information like database credentials and API keys as part of error messages, stack traces, and other forms of data returned to consuming clients.
He explains why process.env feels safe right up until it isn't.
You add dotenv.config() on line one, scatter process.env.DB_PASSWORD across twelve files, then someone's error reporter serialises a request object and your Stripe key ends up in a third-party log.
If you've shipped a Node app, you've probably seen some version of this happen.
On the 31st of March 2026, attackers hijacked an npm maintainer account and published malicious versions of axios with a remote access trojan baked in. npm pulled the bad releases after about two or three hours, but that was enough. Anyone who ran npm install axios during that window could have installed the trojan. The article Post Mortem: axios npm supply chain compromise has all the details.
This kind of attack keeps happening and the playbook barely changes: compromise an account, push a malicious update, hope people install it before anyone notices, get removed a few hours later.
Every major package manager now lets you defend against this. In this post I'll show you the setup for npm, pnpm, Bun and Yarn.
You choose a direction with incomplete information, under time pressure, and with trade-offs you cannot fully test in advance.
That does not make the decision weak.
It makes it real.
In a previous post, I wrote about how design by committee leaves engineering change unfinished. The deeper reason is simple: many organisations treat technical decisions as though they should be certain before the work begins. But most meaningful engineering decisions are not certainties. They are bets.
Engineering change often gets stuck for the same reason: design by committee. Not because anyone has bad intentions, but because the pursuit of alignment quietly replaces the pursuit of learning.
It usually starts with good intentions. People want alignment, consistency, and lower risk. So a proposed change gets pulled into more meetings, more reviews, more stakeholders. Before long, the goal is no longer to try something, learn from it, and improve it. The goal becomes finding one perfect solution for every team.
Strong opinions should be earned, not borrowed. If you want to propose a change, do the work first.
Understand the trade-offs before you walk into the room.
I see the same pattern again and again in software teams. Someone reads a blog post, watches a conference talk, picks up a new buzzword, or sees how a company like Spotify talks about working, and by the next meeting they are proposing that the whole team change how it works.
The idea often sounds compelling at first. But the moment you ask about the trade-offs, the case falls apart. There is no real research, no serious risk assessment, and no clear plan for what to do if the change creates new problems rather than solving the old ones.
That gap between enthusiasm and understanding is where teams get into trouble.
Just because two pieces of code look the same does not mean they are the same.
The most common architecture mistake is not too little abstraction. It is too much, too early. You see duplication, you extract a shared module, and six months later that module is a monster held together by special cases and boolean flags.
Dan Abramov gave a talk about this called The Wet Codebase. The core argument: the wrong abstraction is far more expensive than duplication. Once an abstraction exists, it creates inertia. Nobody wants to be the person who suggests copy-paste.
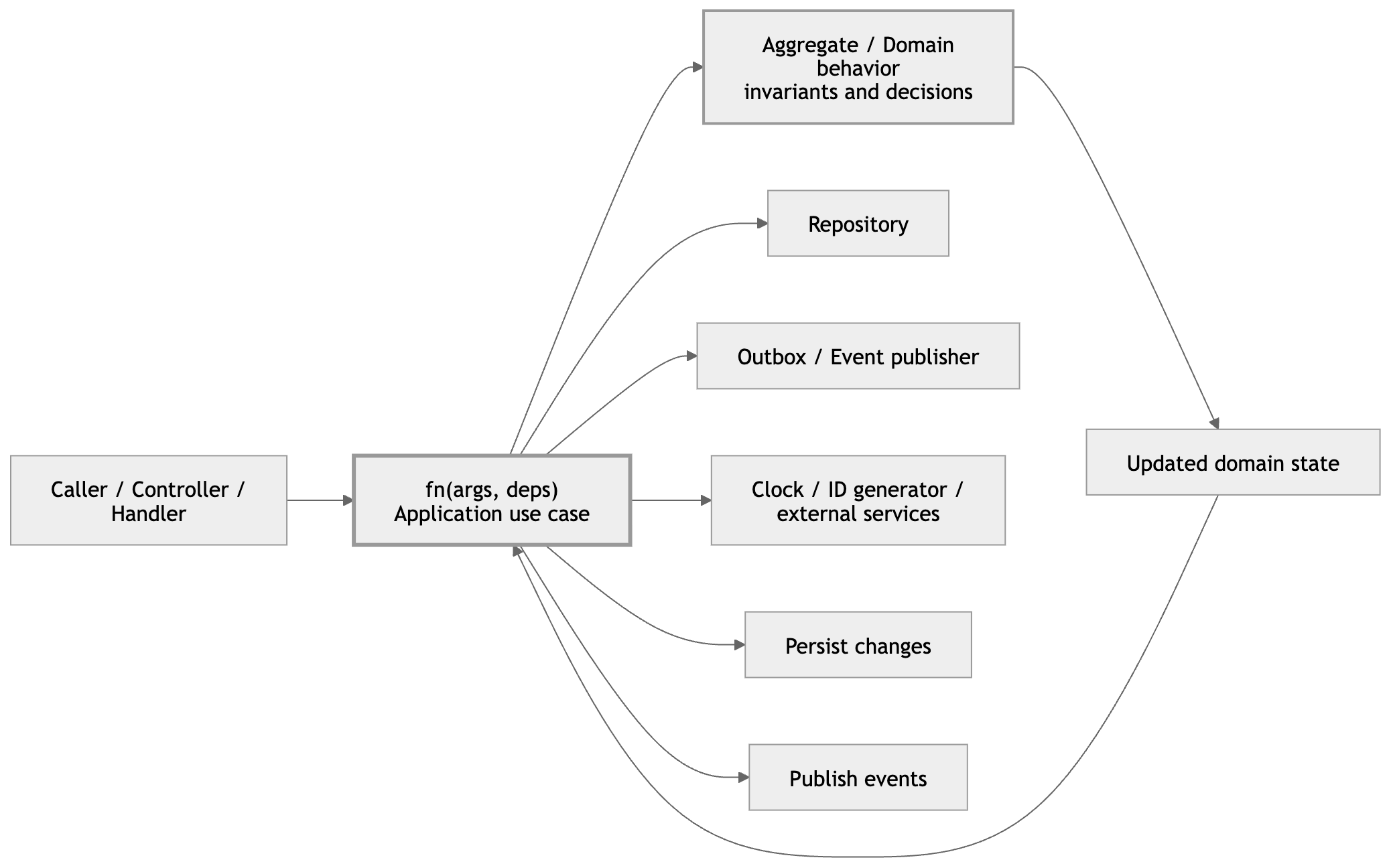
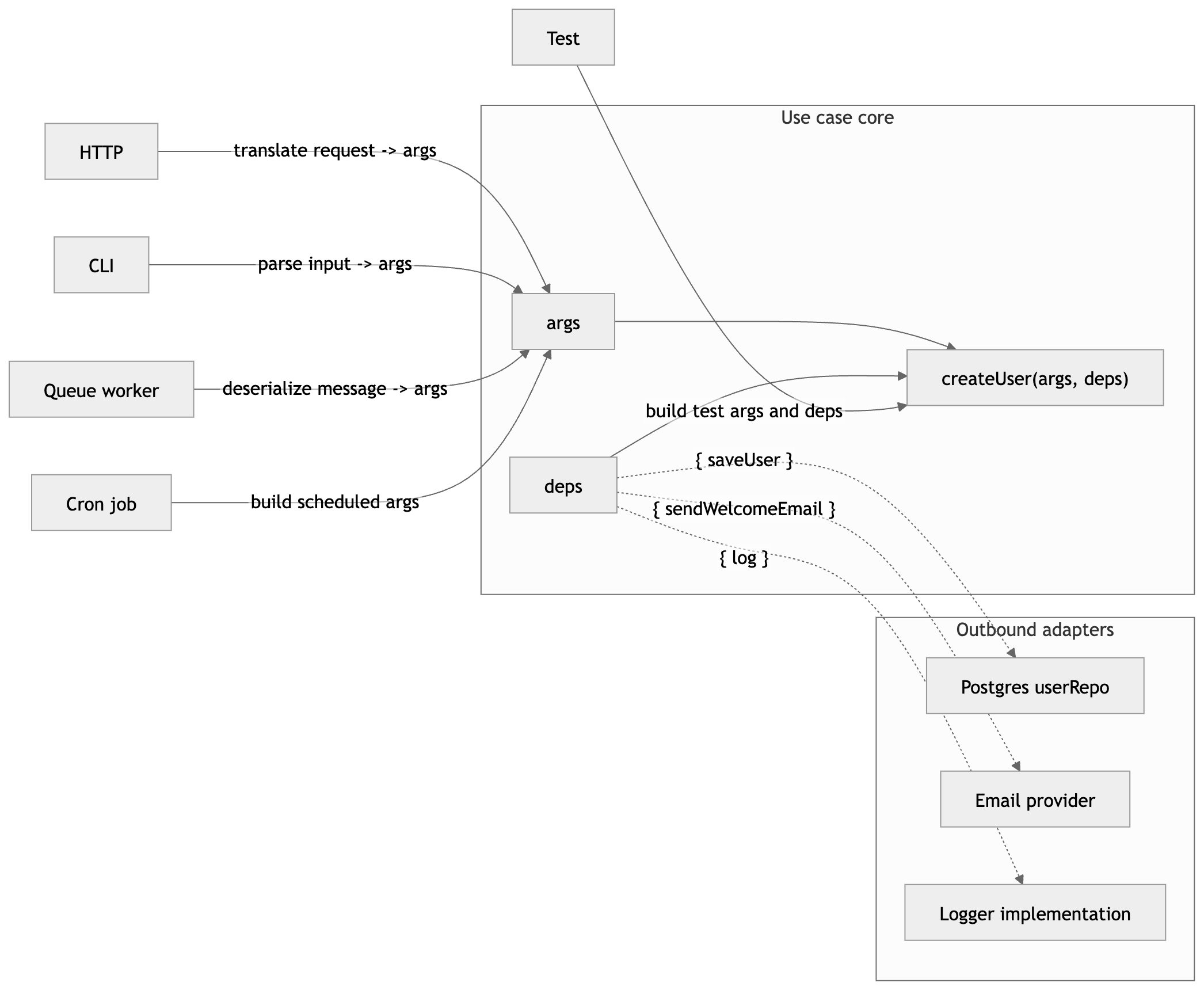
fn(args, deps) changes this calculus. It makes abstractions cheap to create, cheap to test, and cheap to undo.
When a function's deps grow too large, that can be a signal that some responsibility has stabilized into its own function — and that new function itself follows fn(args, deps). (This is basically SRP pressure showing up in your signature; see the SOLID post for that framing.)
Russian dolls. Each layer independently testable. Each layer reversible.
Many software systems fail for one very boring reason.
Not because of microservices. Not because of monoliths. Not because of whatever methodology war is trending this week.
They fail because they are unpredictable.
If you make a change and you cannot reliably determine the impact, you cannot safely evolve the system. And when you cannot evolve it, it starts behaving like legacy.
Determinism is the bridge between "works on my machine" and "works every time, everywhere."
fn(args, deps) gets you there — not because it is a clever trick, but because it makes boundaries explicit. Your logic programs to interfaces, which is what lets you control sources of nondeterminism.
A lot of developers learn the SOLID principles through class-heavy examples.
That is probably why the conversation so often gets stuck there.
People start to associate SOLID with inheritance hierarchies, interface forests, service classes, and object-oriented ceremony.
But the useful part is not the ceremony.
It is the design pressure.
One of the simplest ways to apply that pressure in plain TypeScript is this shape:
fn(args, deps)
Where args is the input for this call and deps is the set of collaborators the function needs.
You can read that as: data in, capabilities in.
fn(args, deps) is not a replacement for SOLID. It is a simple function shape that makes several SOLID ideas easier to apply without forcing you into class-heavy design.
There’s a major disconnect in AI-assisted development right now. Most of the conversation assumes you’re building something new, or working from the kind of clean, stable foundation that barely exists in real engineering teams.
The reality is that most engineering teams live in legacy systems under high load, with god classes, global singletons, and console.log as observability. The kind of code where every change is a gamble.
This post shows what happens when you apply fn(args, deps) and autotel to those codebases. fn(args, deps) creates the seam for safe change; production telemetry captures the behavioural record that survives when every other spec has decayed.
To prove the point, we’ll do this in plain JavaScript, not TypeScript.
Domain-Driven Design comes with a lot of vocabulary: aggregates, repositories, domain services, bounded contexts, ubiquitous language, anemic models.
That vocabulary can make DDD sound heavier than it really is.
The useful idea is simpler: keep domain behavior and domain boundaries central, and keep infrastructure, persistence, and framework wiring secondary.
fn(args, deps) does not do that modeling for you. What it gives you is a clear shape for application-layer code in TypeScript: one place for use-case input, one place for collaborators, and less room for domain decisions to drift into wiring.
A lot of developers hear "dependency injection" and immediately think of containers, decorators, registration APIs, lifecycle scopes, and framework magic.
That reaction is understandable.
But that association often leads people to overcomplicate a problem that has a much simpler starting point.
At its core, dependency injection just means this:
Pass collaborators in explicitly instead of reaching for them implicitly.
One of the simplest ways to do that in plain TypeScript is this shape (introduced in the series starting point: fn(args, deps)):
fn(args, deps)
Where args is call-specific input and deps is the set of collaborators the function needs.
You can read that as: data in, capabilities in.
fn(args, deps) is flexible enough to support composition, testing, and clean application wiring without forcing you into a DI framework.
AI coding agents produce code faster than you can review and understand it.
One pattern works in both new and legacy codebases because you can adopt it incrementally, without breaking callers.
For business logic, treat every function as having two inputs: data (args) and capabilities (deps).
Without a clear constraint, generated code becomes harder to reason about: dependencies disappear, side effects spread, composition gets messy. This is why visible structure is essential.
You have an Awaitly workflow: a few steps, some dependencies, typed results. It works. When someone asks "what does this do?" or you need to debug a run, you're left tracing through code.
What if you could see the same workflow as a diagram? awaitly-visualizer plugs into your workflow's events and turns them into that picture. For a checkout that runs fetchCart, validateCart, processPayment, then completeOrder, you get output like this:
Same idea as Mermaid flowcharts: steps, order, success and failure. This post walks through adding it step by step. All of the code below lives in a test in the repo so you can run it yourself.
As of today, Opus 4.5 is the best coding model I've used. That is not praise by vibes. That is, after building libraries and utilities that fixed problems I could not solve with the tools I was using before.
The progress is impressive.
However, it’s not all sunshine and rainbows, as people on social media and YouTube claim.
constlambdaHandler=async()=>{try{const db =awaitconnectToDb();const result =awaiterrorHandler({ taskId, error },{ db });return{ statusCode:200, body:{ message:'Success', task: result }};}catch(error){return{ statusCode:500, body:{ message:'Error'}};}}
That catch (error) swallows everything. Was it a "task not found"? A database connection failure? A permissions issue? Who knows.
Throwing exceptions for expected failures is like using GOTO. You lose the thread.
Awaitly fixes this by treating errors as data, not explosions. This guide teaches the patterns one concept at a time.
Inject trace context on the producer, extract on the consumer; use PRODUCER and CONSUMER span kinds; set semantic conventions (messaging.system, messaging.destination.name, messaging.operation, Kafka partition/offset/consumer group).
They show the raw OpenTelemetry code. It's comprehensive. It's also verbose. Every team ends up re-implementing the same patterns: inject, extract, span kinds, semantic attributes, error handling.
We've all been there: copying "best practice" code from blog posts and adapting it for our broker.
Their key insight:
For batch processing, use a batch span with links or child spans to contributing traces.
Message isolation using a shared queue: propagate tenant ID in Kafka message headers; consumers use tenant ID for selective message consumption.
They make the case that infrastructure duplication is expensive. Instead of separate Kafka clusters per environment, use tenant ID filtering on a shared queue. Instrument producers and consumers for context propagation.
We've all been there: maintaining four "identical" Kafka setups that slowly drift apart.
Their key insight:
Requires modifying consumers and using OpenTelemetry for context propagation.
Request-level isolation is the most cost-effective approach.
They make the case against duplicating infrastructure for testing. Instead of spinning up separate Kafka clusters per tenant, use OpenTelemetry Baggage to propagate tenant ID through async flows. Consumers filter by tenant ID. Istio handles routing.
We've all been there: every team has their own "staging Kafka" and costs balloon.
Their key insight:
Use OpenTelemetry Baggage to propagate tenant ID through sync and async. When publishing to Kafka, producers inject trace context (including baggage) into message headers; consumers extract and make routing decisions.
Traces break at queues unless you extract context from message headers and put it in the appropriate context.
They walk through the real pain: stateful processing loses trace context in caches, Kafka Connect can only do batch-level tracing, and every team ends up writing custom interceptors and state store wrappers.
We've all been there.
Their key insight:
In Kafka Streams and Kafka Connect this often means manual work: interceptors, state stores, batch spans, or extending tracing logic to extract from headers.
Reranking improves search relevance by reordering documents based on their relevance to a query. Unlike embedding-based similarity search, reranking models are specifically trained to understand the relationship between queries and documents, often producing more accurate relevance scores.
AI coding agents aren't going anywhere. They're excellent at exploring ideas, generating boilerplate, and moving fast. But speed without reliability just ships bugs faster. And without constraints, AI-generated code is unreliable by default.
Coding agents are here to stay, and I know I’m absolutely right about that. While we're all getting used to workflows using AI-powered coding agents, we now live in the world of dark arts and rituals.
We spend hours tweaking prompts, creating elaborate Claude.md, Agents.md and other files formatted in a particular way, stored in a particular way essentially performing black magic to hope our LLM agent adheres to our team's best practices and coding patterns.
On a good day, it works. On others, the behaviour is random.
Here's the problem: Random is not good enough for production.
We're trying to force a non-deterministic, generative tool to be a deterministic rule-follower. This is the wrong approach.
Instead, we should let AI do what it does best: be creative and generative, helping us achieve and realise our desired outcomes while following instructions and examples for how, what, and where it should generate.
My advice? Stop relying on hope-driven prompting. Start using linters to guarantee your standards.
For most of us, AI still feels like a black box. We send it a prompt and we get back a blob of text. Maybe we write some code to call a tool; maybe we juggle a few callbacks. We tell ourselves that this is just how things work: a model can only generate tokens, and tools can only run in our code.
But what if this mental model is the problem?
In this post I want to argue that the Agent pattern in the AI SDK is as revolutionary for AI development as useState and useEffect were for React. Just like React's client/server directives annotate where code runs across the network, the Agent API annotates where logic runs across the AI/model boundary.
Having recently built an AI Guardrails library for the AI SDK, I wanted to share what I learned along the way. This post will walk you through how you can write your own middleware, and why it's such a game-changer for building robust AI applications.
Design AI features that are safer, faster, and easier to evolve by layering language model middleware. This guide explains how to use AI SDK middleware to transform inputs, post-process outputs, enforce safety rules, cache results, observe performance, and handle streaming using a clean, composable approach aligned with official guidance.
When building AI agents, where do your prompts live? If they're hidden inside frameworks or scattered across configuration files, you're missing a fundamental principle of maintainable AI systems: treating prompts as first-class code citizens.
⚽️ Dropped by then and current manager Sarina Wiegman from the England squad in 2022 amid concerns over her attitude and conduct, she remained outside the national setup for almost two years.
⚽️ Born with strabismus and challenged by depth‑perception issues, she was told by doctors she should not play football.
⚽️ Rebuilt her career at Chelsea, playing an integral role in winning the treble last season.
⚽️ Chosen as England's first-choice goalkeeper ahead of the great and brilliant Mary Earps.
⚽️ Delivered under pressure in the quarter‑final versus Sweden, even with a bloody nose. Named Player of the Match.
Tonight, she starts in a European final for England.
Even when things don’t go your way, never give up.
After building production AI systems over the past few years, thanks to HumanLayer, I’ve learned that most agent failures aren’t about the LLM, they’re about architecture.
That’s why I’m creating a series of posts sharing the 12-Factor Agents methodology using Mastra.
In each part, I’ll break down one principle that transforms fragile prototypes into robust, production-ready AI agents.
Unlock reliable, testable AI agents by treating your LLM as a parser, not an executor. Learn how converting natural language into structured tool calls leads to predictable, scalable systems.