A lot of developers hear "dependency injection" and immediately think of containers, decorators, registration APIs, lifecycle scopes, and framework magic.
That reaction is understandable.
But that association often leads people to overcomplicate a problem that has a much simpler starting point.
At its core, dependency injection just means this:
Pass collaborators in explicitly instead of reaching for them implicitly.
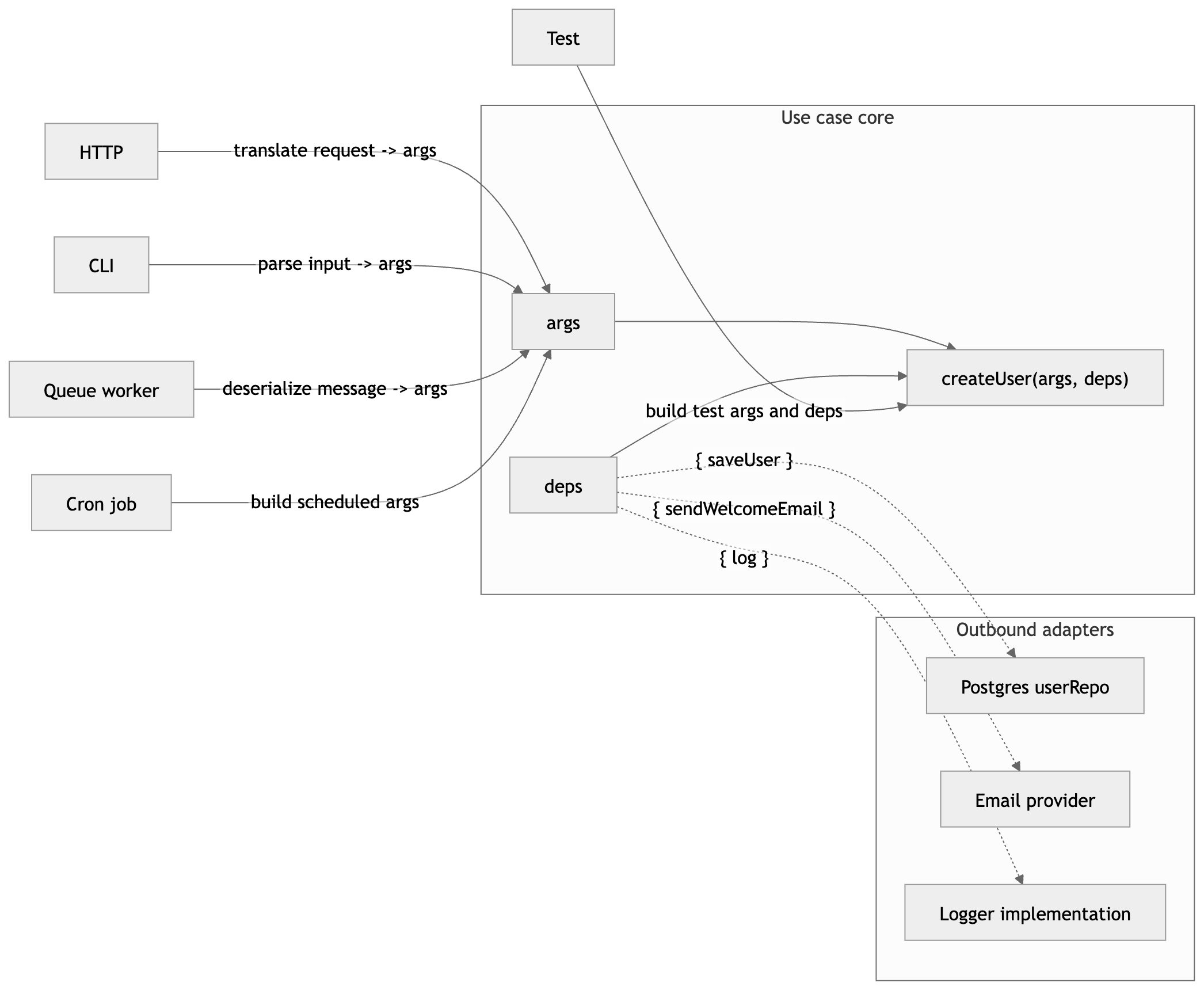
One of the simplest ways to do that in plain TypeScript is this shape (introduced in the series starting point: fn(args, deps)):
fn(args, deps)
Where args is call-specific input and deps is the set of collaborators the function needs.
You can read that as: data in, capabilities in.
fn(args, deps) is flexible enough to support composition, testing, and clean application wiring without forcing you into a DI framework.
AI coding agents produce code faster than you can review and understand it.
One pattern works in both new and legacy codebases because you can adopt it incrementally, without breaking callers.
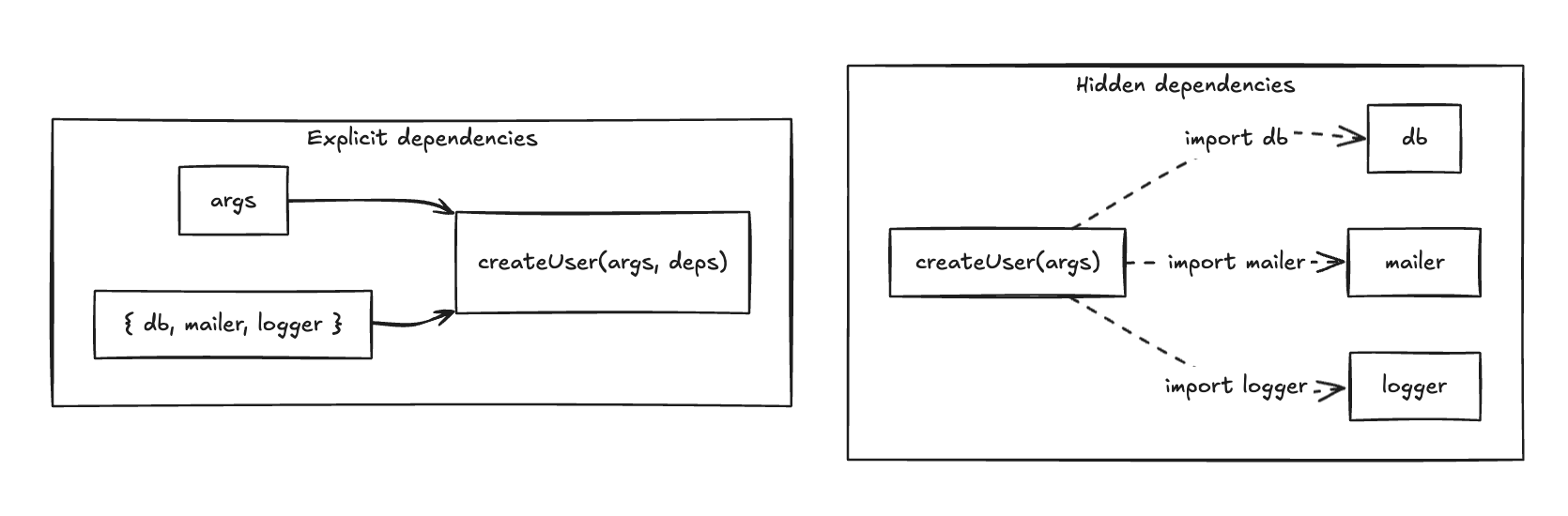
For business logic, treat every function as having two inputs: data (args) and capabilities (deps).
Without a clear constraint, generated code becomes harder to reason about: dependencies disappear, side effects spread, composition gets messy. This is why visible structure is essential.
You have an Awaitly workflow: a few steps, some dependencies, typed results. It works. When someone asks "what does this do?" or you need to debug a run, you're left tracing through code.
What if you could see the same workflow as a diagram? awaitly-visualizer plugs into your workflow's events and turns them into that picture. For a checkout that runs fetchCart, validateCart, processPayment, then completeOrder, you get output like this:
Same idea as Mermaid flowcharts: steps, order, success and failure. This post walks through adding it step by step. All of the code below lives in a test in the repo so you can run it yourself.
As of today, Opus 4.5 is the best coding model I've used. That is not praise by vibes. That is, after building libraries and utilities that fixed problems I could not solve with the tools I was using before.
The progress is impressive.
However, it’s not all sunshine and rainbows, as people on social media and YouTube claim.
constlambdaHandler=async()=>{try{const db =awaitconnectToDb();const result =awaiterrorHandler({ taskId, error },{ db });return{ statusCode:200, body:{ message:'Success', task: result }};}catch(error){return{ statusCode:500, body:{ message:'Error'}};}}
That catch (error) swallows everything. Was it a "task not found"? A database connection failure? A permissions issue? Who knows.
Throwing exceptions for expected failures is like using GOTO. You lose the thread.
Awaitly fixes this by treating errors as data, not explosions. This guide teaches the patterns one concept at a time.
Inject trace context on the producer, extract on the consumer; use PRODUCER and CONSUMER span kinds; set semantic conventions (messaging.system, messaging.destination.name, messaging.operation, Kafka partition/offset/consumer group).
They show the raw OpenTelemetry code. It's comprehensive. It's also verbose. Every team ends up re-implementing the same patterns: inject, extract, span kinds, semantic attributes, error handling.
We've all been there: copying "best practice" code from blog posts and adapting it for our broker.
Their key insight:
For batch processing, use a batch span with links or child spans to contributing traces.