Strong opinions should be earned, not borrowed. If you want to propose a change, do the work first.
Understand the trade-offs before you walk into the room.
I see the same pattern again and again in software teams. Someone reads a blog post, watches a conference talk, picks up a new buzzword, or sees how a company like Spotify talks about working, and by the next meeting they are proposing that the whole team change how it works.
The idea often sounds compelling at first. But the moment you ask about the trade-offs, the case falls apart. There is no real research, no serious risk assessment, and no clear plan for what to do if the change creates new problems rather than solving the old ones.
That gap between enthusiasm and understanding is where teams get into trouble.
Just because two pieces of code look the same does not mean they are the same.
The most common architecture mistake is not too little abstraction. It is too much, too early. You see duplication, you extract a shared module, and six months later that module is a monster held together by special cases and boolean flags.
Dan Abramov gave a talk about this called The Wet Codebase. The core argument: the wrong abstraction is far more expensive than duplication. Once an abstraction exists, it creates inertia. Nobody wants to be the person who suggests copy-paste.
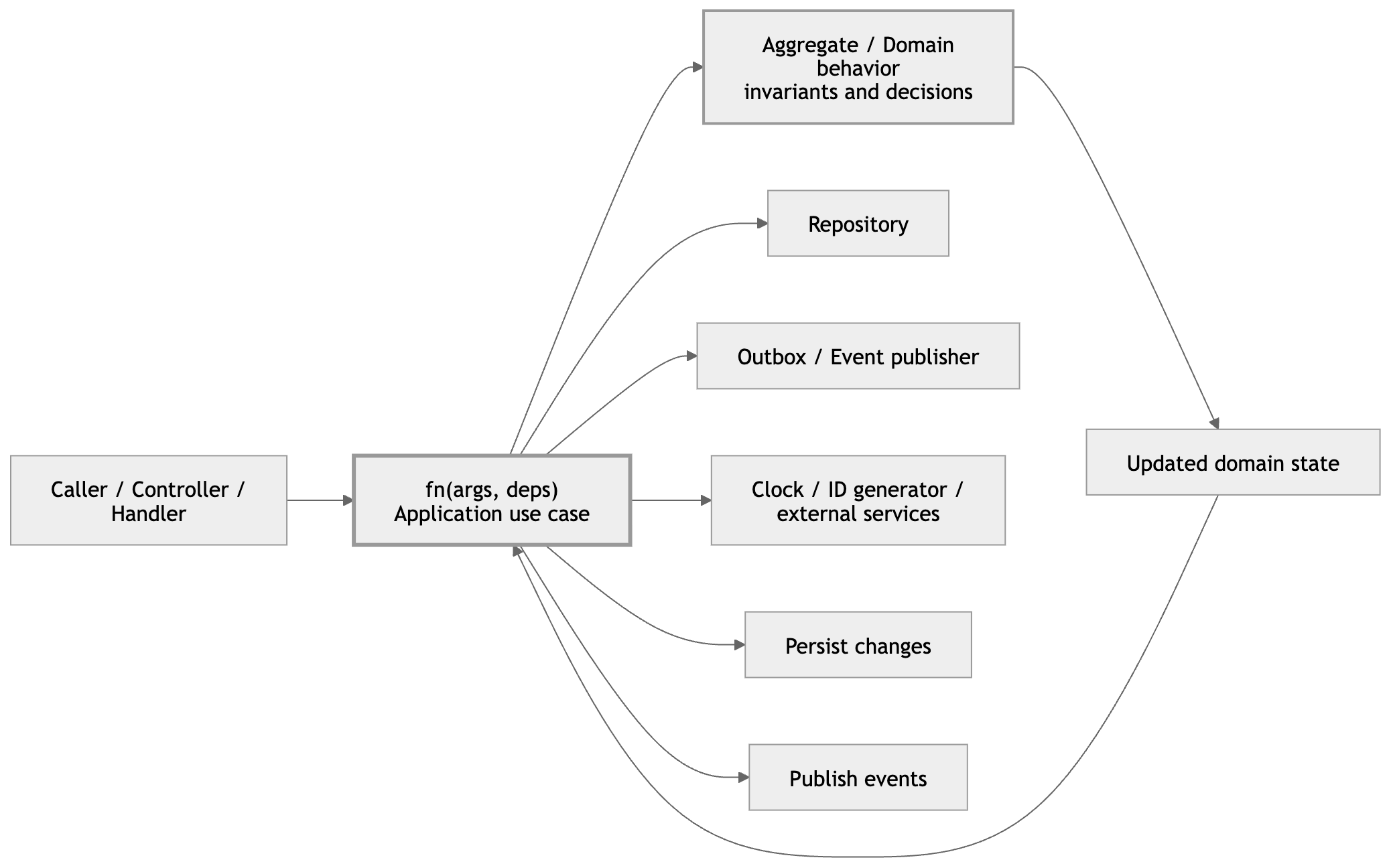
fn(args, deps) changes this calculus. It makes abstractions cheap to create, cheap to test, and cheap to undo.
When a function's deps grow too large, that can be a signal that some responsibility has stabilized into its own function — and that new function itself follows fn(args, deps). (This is basically SRP pressure showing up in your signature; see the SOLID post for that framing.)
Russian dolls. Each layer independently testable. Each layer reversible.
Many software systems fail for one very boring reason.
Not because of microservices. Not because of monoliths. Not because of whatever methodology war is trending this week.
They fail because they are unpredictable.
If you make a change and you cannot reliably determine the impact, you cannot safely evolve the system. And when you cannot evolve it, it starts behaving like legacy.
Determinism is the bridge between "works on my machine" and "works every time, everywhere."
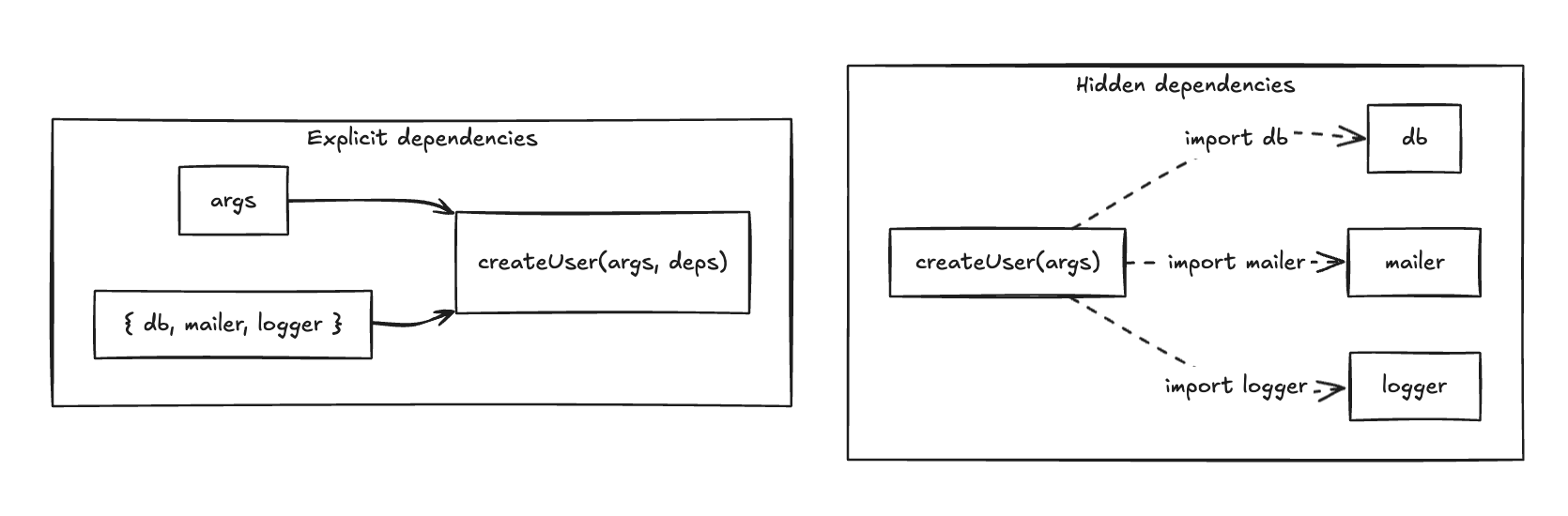
fn(args, deps) gets you there — not because it is a clever trick, but because it makes boundaries explicit. Your logic programs to interfaces, which is what lets you control sources of nondeterminism.
A lot of developers learn the SOLID principles through class-heavy examples.
That is probably why the conversation so often gets stuck there.
People start to associate SOLID with inheritance hierarchies, interface forests, service classes, and object-oriented ceremony.
But the useful part is not the ceremony.
It is the design pressure.
One of the simplest ways to apply that pressure in plain TypeScript is this shape:
fn(args, deps)
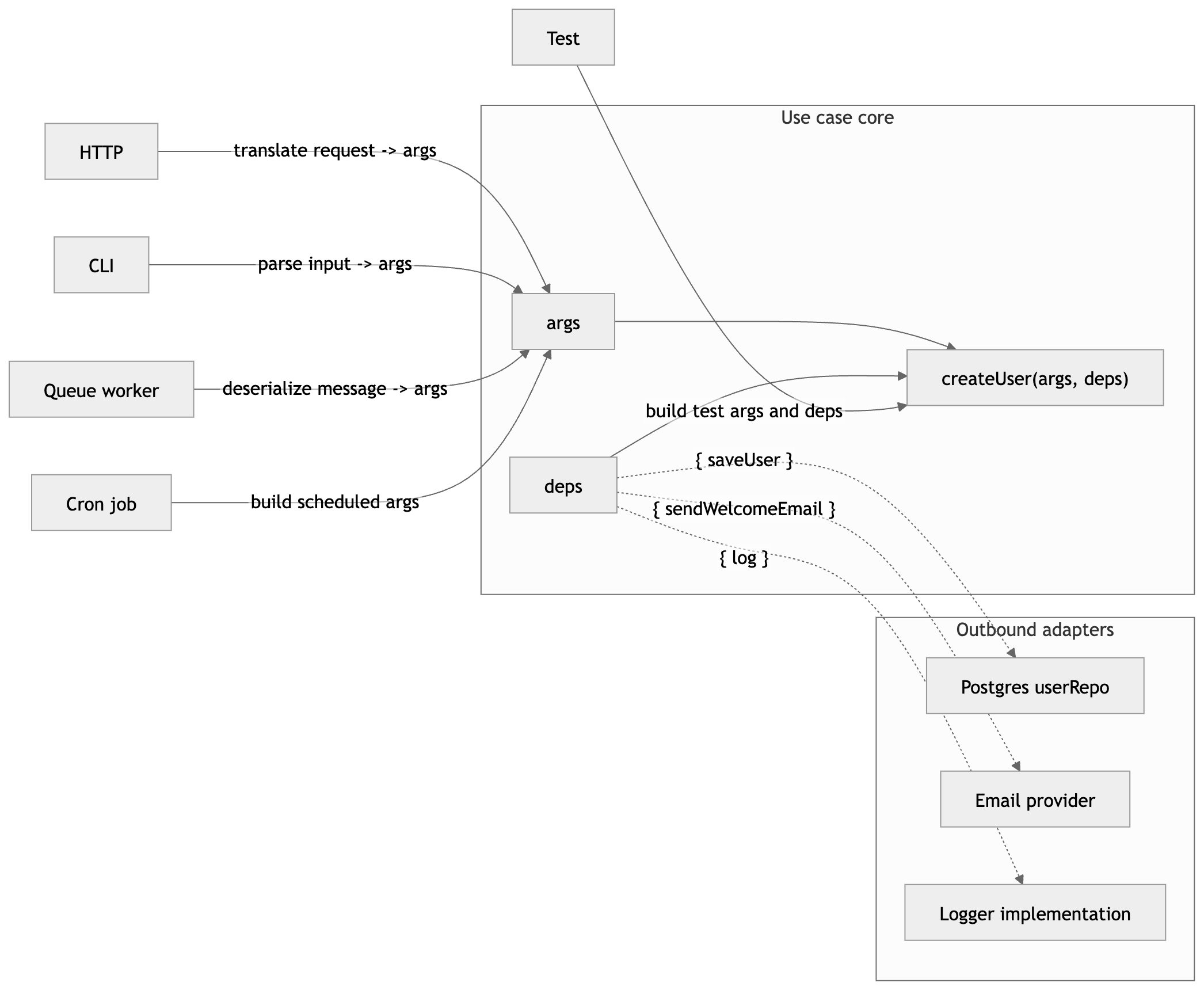
Where args is the input for this call and deps is the set of collaborators the function needs.
You can read that as: data in, capabilities in.
fn(args, deps) is not a replacement for SOLID. It is a simple function shape that makes several SOLID ideas easier to apply without forcing you into class-heavy design.
There’s a major disconnect in AI-assisted development right now. Most of the conversation assumes you’re building something new, or working from the kind of clean, stable foundation that barely exists in real engineering teams.
The reality is that most engineering teams live in legacy systems under high load, with god classes, global singletons, and console.log as observability. The kind of code where every change is a gamble.
This post shows what happens when you apply fn(args, deps) and autotel to those codebases. fn(args, deps) creates the seam for safe change; production telemetry captures the behavioural record that survives when every other spec has decayed.
To prove the point, we’ll do this in plain JavaScript, not TypeScript.
Domain-Driven Design comes with a lot of vocabulary: aggregates, repositories, domain services, bounded contexts, ubiquitous language, anemic models.
That vocabulary can make DDD sound heavier than it really is.
The useful idea is simpler: keep domain behavior and domain boundaries central, and keep infrastructure, persistence, and framework wiring secondary.
fn(args, deps) does not do that modeling for you. What it gives you is a clear shape for application-layer code in TypeScript: one place for use-case input, one place for collaborators, and less room for domain decisions to drift into wiring.
A lot of developers hear "dependency injection" and immediately think of containers, decorators, registration APIs, lifecycle scopes, and framework magic.
That reaction is understandable.
But that association often leads people to overcomplicate a problem that has a much simpler starting point.
At its core, dependency injection just means this:
Pass collaborators in explicitly instead of reaching for them implicitly.
One of the simplest ways to do that in plain TypeScript is this shape (introduced in the series starting point: fn(args, deps)):
fn(args, deps)
Where args is call-specific input and deps is the set of collaborators the function needs.
You can read that as: data in, capabilities in.
fn(args, deps) is flexible enough to support composition, testing, and clean application wiring without forcing you into a DI framework.